



汉语—阿拉伯语多源平行数据库CAMP V1.0发布
时间: 2022-08-10 12:00:00 来源:作者:
汉语—阿拉伯语多源平行数据库(Chinese Arabic Multi-Resources Parallel Database,CAMP Database)是一个语料领域、媒介、主题、体裁、时期等方面都来源丰富多样的数据库,其组成包括基础的多个平行语料库和基于平行数据经标注、加工处理建构的一系列平行知识库。本次发布的V1.0版本包含习近平主席重要讲话和中国政府历年工作报告两个平行语料库,以及基于这两个语料库建设的多个平行知识库。CAMP库具有动态属性,后续将不断更新语料来源和加工,以及支持数据检索和可视化功能的平台,可为翻译、智能外语教学、数字人文等领域的研究者们提供数据支撑。
CAMP库由北京大学外国语学院阿拉伯语系教师Alaa Mamdouh Akef(高山)组建的汉阿—阿汉语言资源团队(Chinese Arabic Language Resource Group,CARG)构建。团队其他成员有北京语言大学博士生王莹莹、北京师范大学博士生Shawky Nasr(邵基)、埃及艾因夏姆斯大学语言学院中文系副讲师Aya Mohamed EL-Ghazy(李诗琪)。
CAMP库是小语种平行数据资源建构和应用研究的一次路径探索,是来自中国和阿拉伯国家的计算语言学这一交叉领域的研究者们的一次合作尝试,可为其他语种的资源建构提供案例参考,共同促进外语研究数据化和智能化。
//

图1 CAMP库架构图
习近平主席重要讲话平行语料库采集了习近平主席于2013年至今公开发表的一系列重要讲话,以及对应的阿拉伯语翻译。文章来自《习近平谈治国理政》第一卷、第二卷、第三卷和《论坚持推动构建人类命运共同体》的阿拉伯语译本,以及新华网、人民网、中国环球电视网等媒体官方网站的阿拉伯语版本或者频道,去重后共343篇文章2万余平行句对,覆盖2013—2022年的10年时间,并将不断更新。
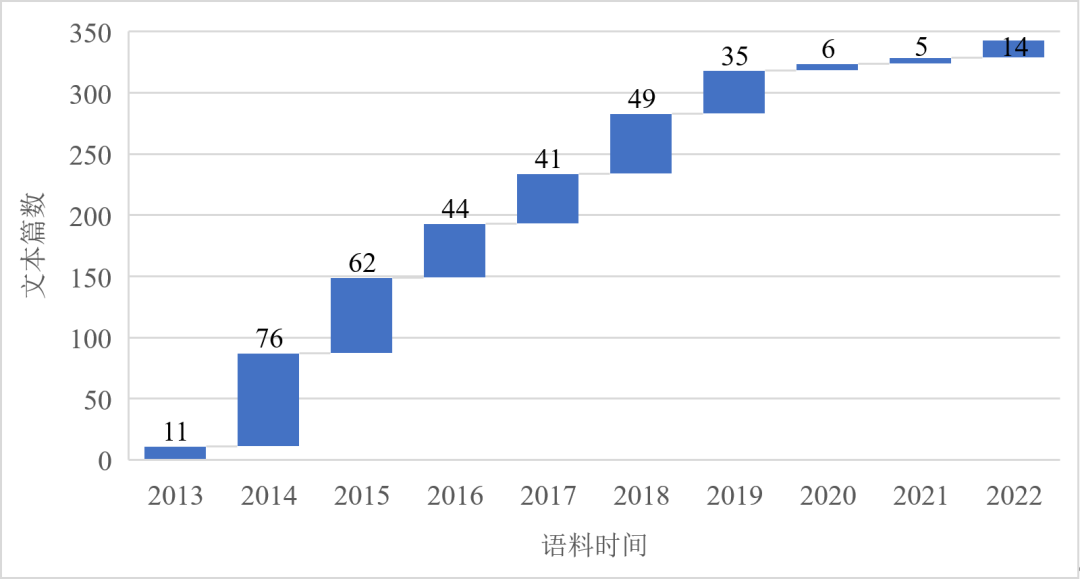
图2 习近平主席重要讲话平行语料库
历年语料分布图
中国政府历年工作报告平行语料库采集了从2013—2022年的中国政府工作报告及对应的阿拉伯语翻译,共5千余平行句对。
语料采集后使用开源工具对汉语和阿拉伯语的单语数据进行包括预处理、自动分句、分词、词形还原(阿语)、词性标注、短语句法分析、依存句法分析等加工,以及对双语数据进行篇章、段落、句子的层级对齐。最终得到的语料按照不同来源使用结构化的存储方式,保存每篇讲话的题目、时间、类别(可选)、段落、注释等信息,后续可进一步建立索引文件,作为语料检索平台的后台数据使用。数据文件存储示例如下:

图3 平行语料库数据示例
CAMP库的数据资源仅限于学术研究,如需使用,请邮件联系数据研发团队负责人alaa_eldin_akef@pku.edu.cn 阐述研究需求。